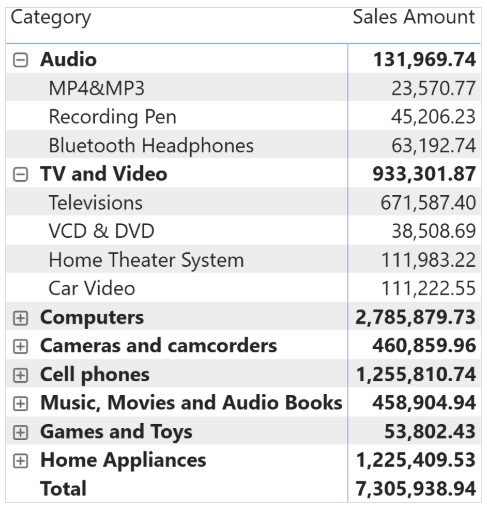
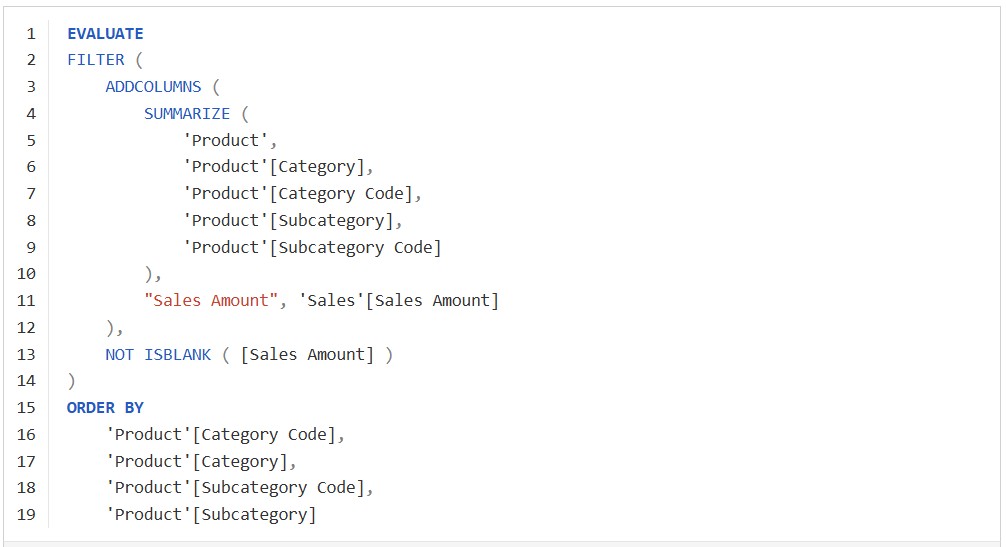
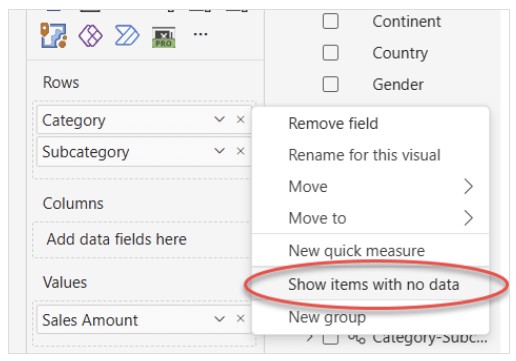
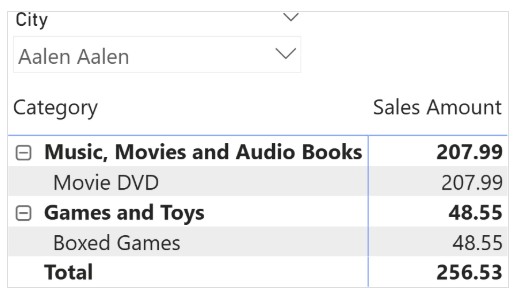
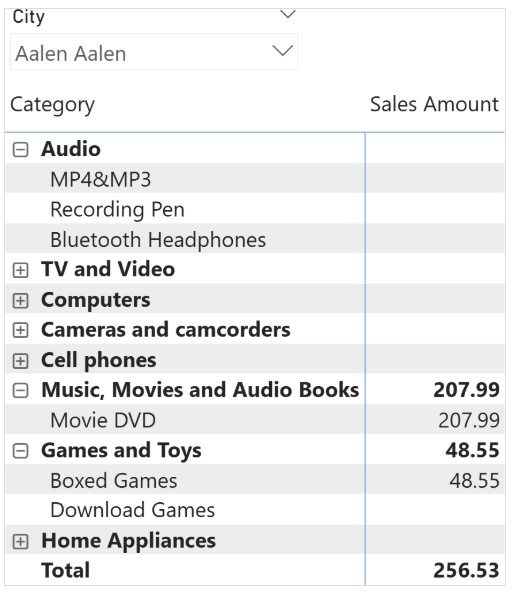
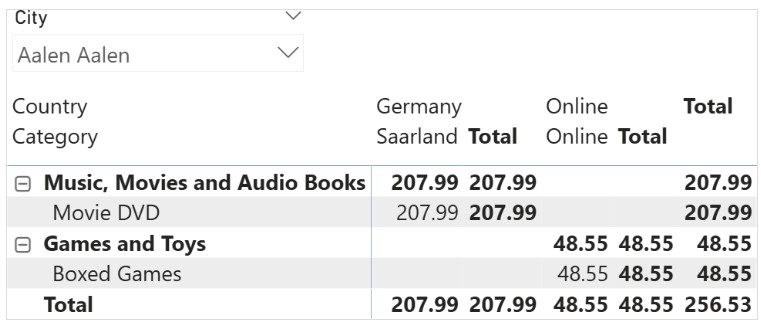
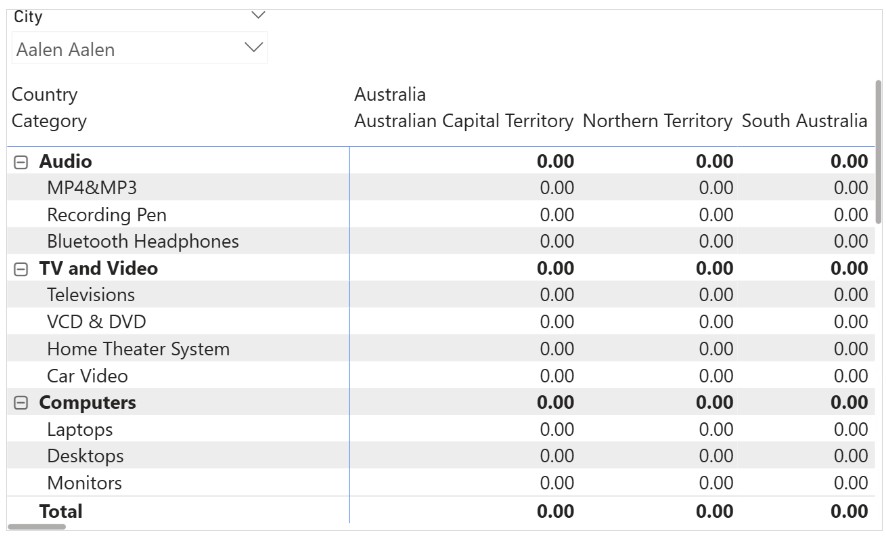
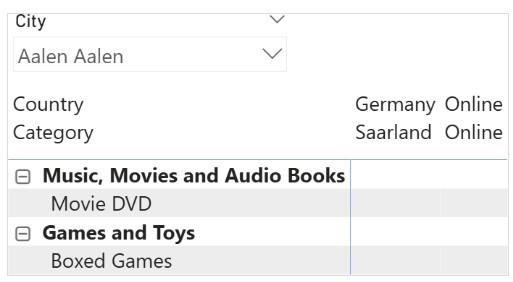
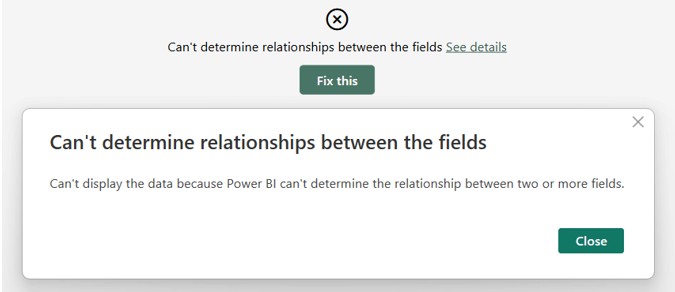
درک خطای “can’t determine relationship between the fields” در Power BI





مطالب آموزشی



دیدگاهتان را بنویسید