تابع SUMMARIZECOLUMNS پرکاربردترین تابع در کوئریهای Power BI است. یکی از ویژگیهای مهم و منحصربهفرد آن، توانایی تعیین خودکار نحوه اسکن مدل داده برای تولید خروجی است.
در حالی که هنگام استفاده از توابعی مانند SUMMARIZE، GROUPBY، ADDCOLUMNS یا سایر توابع پایه کوئرینویسی، توسعهدهنده باید جدول منبع، ستونهای گروهبندی (Group-by) و معیارها (Measures) را مشخص کند، در SUMMARIZECOLUMNS تنها کافی است ستونهای گروهبندی را تعریف کنید. این تابع نیازی به تعیین جدول منبع ندارد و با الگوریتم پیشرفته خود، ساختار خروجی را به صورت خودکار تشخیص میدهد؛ موضوعی که نیاز به درک عمیق از عملکرد آن دارد.
فهرست مطالب
چرا SUMMARIZECOLUMNS در DAX اهمیت بیشتری پیدا کرده است؟
با وجود اینکه SUMMARIZECOLUMNS سالهاست به عنوان یکی از توابع DAX وجود دارد، بسیاری از توسعهدهندگان DAX هنوز با تمام قابلیتهای آن آشنا نیستند. دلیل این موضوع ساده است: قبل از سال 2025، امکان استفاده از SUMMARIZECOLUMNS در Measures وجود نداشت. این تابع تقریباً بهطور انحصاری توسط Power BI برای پر کردن دادههای ویژوالها استفاده میشد.
از آنجا که توسعهدهندگان DAX بیشتر به نوشتن Measures میپردازند تا کوئریها، و SUMMARIZECOLUMNS هم تا آن زمان در Measures قابل استفاده نبود، عملاً دلیلی برای یادگیری کامل آن وجود نداشت.
دلیل محدودیت قبلی
این محدودیت بسیار فنی بود و حالا دیگر وجود ندارد. در گذشته، SUMMARIZECOLUMNS نمیتوانست درون یک حلقه تکرار (Iteration) یا درون یک SUMMARIZECOLUMNS دیگر فراخوانی شود. از آنجایی که Measures تقریباً همیشه در Power BI درون یک SUMMARIZECOLUMNS بیرونی اجرا میشوند، طبیعی بود که نتوان این تابع را بهطور مستقیم در Measures استفاده کرد.
رفع محدودیت و تغییرات اخیر
این محدودیت بین سالهای 2023 و 2024 برطرف شد. از سال 2025، SUMMARIZECOLUMNS میتواند به عنوان جایگزینی برای ADDCOLUMNS یا SUMMARIZE در Measures استفاده شود.
با این حال، صرف اینکه استفاده از یک قابلیت امکانپذیر است، به معنای استفاده بیقید و شرط از آن نیست. SUMMARIZECOLUMNS در ایجاد خروجی بسیار پیچیده عمل میکند، بهگونهای که توصیه میکنیم تنها از بخشهای مشخص و کاربردی آن استفاده شود.
تابع SUMMARIZECOLUMNS در DAX امکانات متنوع و قدرتمندی ارائه میدهد:
گروهبندی بر اساس هر مجموعهای از ستونها، بدون نیاز به مشخص کردن جدول مبدا (برخلاف توابعی مانند SUMMARIZE یا GROUPBY).
گروهبندی با استفاده از روابط محدود (Limited Relationships)، قابلیتی که در توابع سادهتر مانند SUMMARIZE وجود ندارد.
اعمال فیلترها که هم در گروهبندی و هم در محاسبه Measures استفاده میشوند.
محاسبه زیرجمعها (Subtotals) برای ستونها یا گروههایی از ستونها.
افزودن ستونهای جدید به خروجی، با محاسبه عبارات DAX در Filter Context ستونهای گروهبندیشده فعلی.
پشتیبانی از مودیفایرها (Modifiers) برای تغییر رفتار تابع، مانند IGNORE و NONVISUAL.
بیشتر قابلیتهای SUMMARIZECOLUMNS را میتوان با ترکیب توابع سادهتر DAX به دست آورد. به عنوان مثال، کوئری زیر دادهها را بر اساس Product[Brand] و Date[Year] گروهبندی میکند تا مجموع فروش محصولات بنفش را محاسبه کند:
با این حال، این کوئری دوم کاملاً معادل نسخهای که با SUMMARIZECOLUMNS نوشته شده نیست. در این مثال ساده، نتیجه مشابه است، اما در سناریوهای پیچیدهتر کار نخواهد کرد. برای مثال، اگر رابطه بین Sales و Product یک رابطه محدود (Limited Relationship) باشد، این فرمول دوم با خطا مواجه میشود، در حالی که فرمول قبلی (که پیچیدهتر بود) بهراحتی کار خواهد کرد.
مزیت SUMMARIZECOLUMNS این است که تمام قابلیتها را در یک تابع واحد ترکیب میکند. اما همین ویژگی میتواند نقطه ضعف هم باشد؛ چرا که ترکیب همه امکانات در یک تابع واحد، منجر به رفتارهای بسیار پیچیده میشود.
در بیشتر مواقع، SUMMARIZECOLUMNS نتایج مورد انتظار را تولید میکند، اما در برخی سناریوها، خودکارسازیها و مکانیزمهای داخلی آن ممکن است نتایج غیرمنتظرهای به همراه داشته باشد.
بهترین شیوهها برای استفاده از SUMMARIZECOLUMNS
تابع SUMMARIZECOLUMNS هم میتواند برای نوشتن کوئریها استفاده شود و هم برای ایجاد جداول موقت درون Measures با هدف انجام محاسبات بیشتر. نکات زیر در هر دو حالت معتبر هستند، اما اهمیت آنها در استفاده از SUMMARIZECOLUMNS درون Measures بیشتر است. دلیل آن این است که یک Measure باید در هر نوع Evaluation Context به درستی اجرا شود، در حالی که یک کوئری معمولاً در Empty Filter Context اجرا میشود. به همین خاطر، نوشتن Measures نیازمند دقت بیشتری است.
از آنجا که SUMMARIZECOLUMNS تابع اصلی Power BI برای پر کردن گزارشها است، طی سالها بسیار بهینهسازی شده و این روند احتمالاً ادامه خواهد داشت. در اکثر موارد، این تابع عملکردی بهتر از ترکیب توابعی مانند SUMMARIZE، ADDCOLUMNS، GROUPBY و سایر توابع پایه DAX دارد.
به همین دلیل، ممکن است وسوسه شوید که SUMMARIZECOLUMNS را به عنوان تابع اصلی گروهبندی در DAX در نظر بگیرید و از آن به جای توابع سادهتر استفاده کنید. این تابع کوتاه و سریع است، اما با وجود تمام مزایای آن، در برخی سناریوهای خاص، درک عملکردش بسیار پیچیده خواهد بود.
بنابراین، توصیه میکنیم استفاده از SUMMARIZECOLUMNS را به سناریوهای پیشرفته محدود کنید و سناریوهای سادهتر را با توابع معمول DAX انجام دهید.
راهنمای انتخاب تابع در سناریوهای مختلف
گروهبندی ساده بدون Measure
استفاده از VALUES برای یک ستون
استفاده از SUMMARIZE برای مدلهایی که فقط روابط معمولی (Regular Relationships) دارند
استفاده از SUMMARIZECOLUMNS در صورت وجود روابط محدود (Limited Relationships)
گروهبندی ساده همراه با Measure
وقتی گروهبندی و محاسبه Measures فقط بر روی یک Fact Table انجام میشود، SUMMARIZECOLUMNS بهترین گزینه است چون بهینهسازی شدهتر است.
با این حال، عملکرد آن فقط کمی بهتر از SUMMARIZE و ADDCOLUMNS است.
گروهبندی پیچیده
وقتی گروهبندی و محاسبه Measures از چندین Fact Table انجام میشود، SUMMARIZECOLUMNS بهترین انتخاب است، زیرا کد DAX را کوتاه و خوانا میکند.
در مقابل، استفاده از SUMMARIZE و ADDCOLUMNS در این شرایط منجر به کدی پیچیده و طولانی خواهد شد.
گروهبندی همراه با فیلترگذاری
استفاده از SUMMARIZECOLUMNS همچنان گزینه خوبی است.
اما بهتر است بخش فیلترگذاری خارج از SUMMARIZECOLUMNS و در یک CALCULATETABLE جداگانه انجام شود تا از مشکلات مربوط به Coalesced Filters و ستونهای گروهبندی جلوگیری شود.
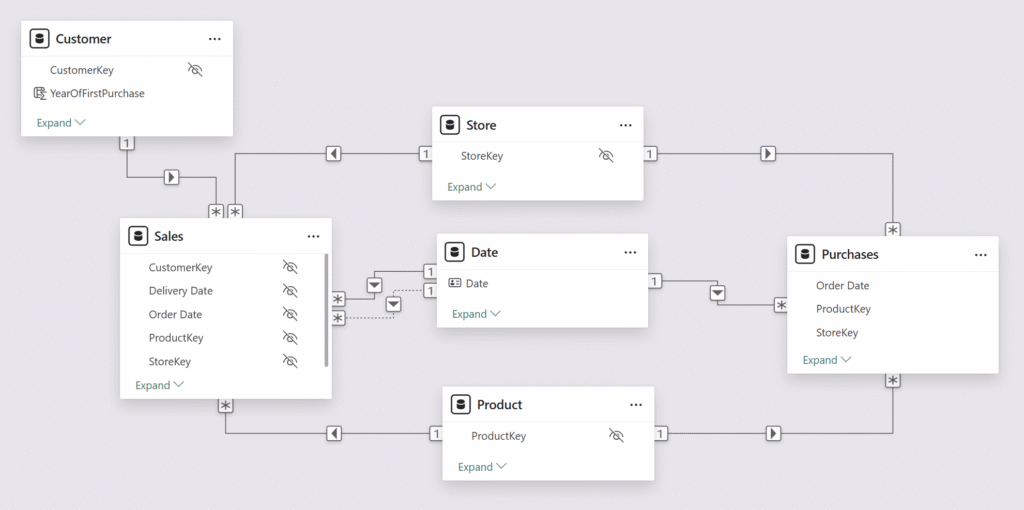
در بخشهای بعدی، جزئیات بیشتری درباره دلایل هر یک از این بهترین شیوهها ارائه میدهیم. مثالها بر اساس یک مدل معنایی (Semantic Model) هستند که در آن Measures دو جدول Sales و Purchases را تجمیع میکنند.
گروهبندی پایه بدون Measure
وقتی نیاز به گروهبندی وجود دارد ولی Measures دخیل نیستند، استفاده از SUMMARIZECOLUMNS اغراقآمیز است. توابع SUMMARIZE یا VALUES کاملاً کافی هستند.
اگر فقط به مقادیر یک ستون نیاز دارید، VALUES بهترین گزینه است.
اگر به ترکیبهای موجود یک مجموعه از ستونها نیاز دارید، SUMMARIZE بهترین انتخاب است.
تنها سناریویی که استفاده از SUMMARIZECOLUMNS برای گروهبندی توصیه میشود، زمانی است که روابط محدود (Limited Relationships) در مدل وجود دارند. در واقع، SUMMARIZE به توسعهدهندگان اجازه میدهد روی هر ستون جدول گسترشیافته گروهبندی کنند. اما اگر مدل شامل روابط محدود باشد، Table Expansion رخ نمیدهد و دیگر SUMMARIZE گزینه مناسبی نخواهد بود. در این شرایط، SUMMARIZECOLUMNS انتخاب برتر است.
از آنجا که Measures وجود ندارد، مکانیزم Non-empty فعال نخواهد شد. بنابراین، همیشه باید از یک جدول برای مشخص کردن نحوه اجرای Auto-exists استفاده کنید تا از تولید Cross-Join کامل مقادیر جلوگیری شود.
در حالی که کوئری اول احتمالاً برای خواننده شهودیتر است، کوئری دوم که از SUMMARIZECOLUMNS استفاده میکند، به همان صورت عمل میکند، حتی اگر جدول Sales را به عنوان فیلتر و نه جدول اصلی گروهبندی استفاده کنیم.
گروهبندی پایه همراه با Measures
متداولترین سناریویی که SUMMARIZECOLUMNS مفید است، زمانی است که نیاز دارید هم بر اساس چند ستون گروهبندی کنید و هم یک Measure را محاسبه کنید و همزمان مقادیر خالی (Empty Values) را حذف نمایید.
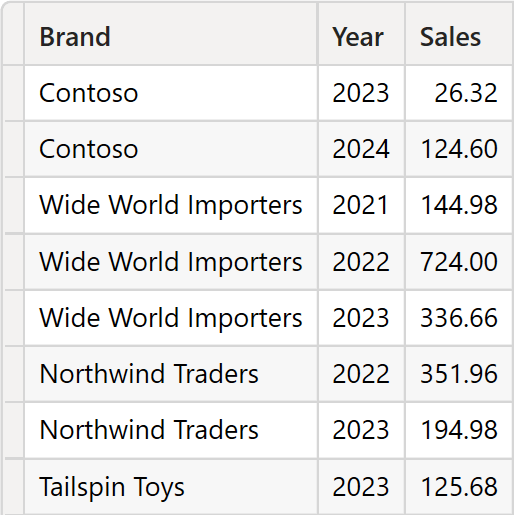
این سناریو اکثر موقعیتهایی که گروهبندی لازم است را پوشش میدهد. به عنوان مثال، دو کوئری زیر تقریباً معادل یکدیگر هستند:
قبل از ادامه، ضروری است توجه کنیم که دو فرمول کاملاً یکسان نیستند.
وقتی از SUMMARIZE استفاده میکنیم، نتیجه شامل تمام ترکیبهای Brand و Continent است که توسط Sales مرجع شدهاند، صرفنظر از مقدار Measure @Sales. به عبارت دیگر، مقادیر موجود ترکیبی بدون توجه به مقدار Measure بازگردانده میشوند.
از سوی دیگر، SUMMARIZECOLUMNS یک Cross-Join کامل از مقادیر ستونها تولید میکند و Measure مسئول تعیین ترکیبهایی است که باید بازگردند. اگر Measure مقدار Blank برگرداند، ترکیب توسط Non-empty حذف میشود، در غیر این صورت، ترکیب حفظ میشود.
تفاوت مهم دیگر
نحوه اعمال فیلتر خارجی (Outer Filter) روی این دو تابع متفاوت است:
SUMMARIZE جدول Sales را اسکن میکند و تمام فیلترهایی که مستقیماً یا غیرمستقیم روی Sales تأثیر دارند را در نظر میگیرد.
SUMMARIZECOLUMNS ترکیبهای گروهبندی را تولید میکند و Cross-filters را نادیده میگیرد و به Measure تکیه میکند تا ترکیبهای غیرضروری را با Non-empty حذف کند.
با توجه به این تفاوتها، هر دو گزینه SUMMARIZECOLUMNS و ADDCOLUMNS / SUMMARIZE مناسب هستند، اما کمی SUMMARIZECOLUMNS ترجیح داده میشود. در واقع، SUMMARIZECOLUMNS یک تابع بهخوبی بهینهشده است و احتمالاً عملکرد آن بهتر از ADDCOLUMNS / SUMMARIZE خواهد بود. با این حال، در زمینه بهینهسازی عملکرد، تست گسترده همیشه ضروری است. بنابراین، توصیه میکنیم خوانندگان هر دو سناریو را آزمایش کرده و تصمیمی آگاهانه بگیرند.
گروهبندی پیچیده
در سناریوهایی که نیاز است گروهبندی انجام شود و مقادیر از چند جدول Fact مختلف تجمیع شوند، SUMMARIZECOLUMNS بدون شک بهترین گزینه است، زیرا ساختن خروجی صحیح را بسیار آسانتر میکند.
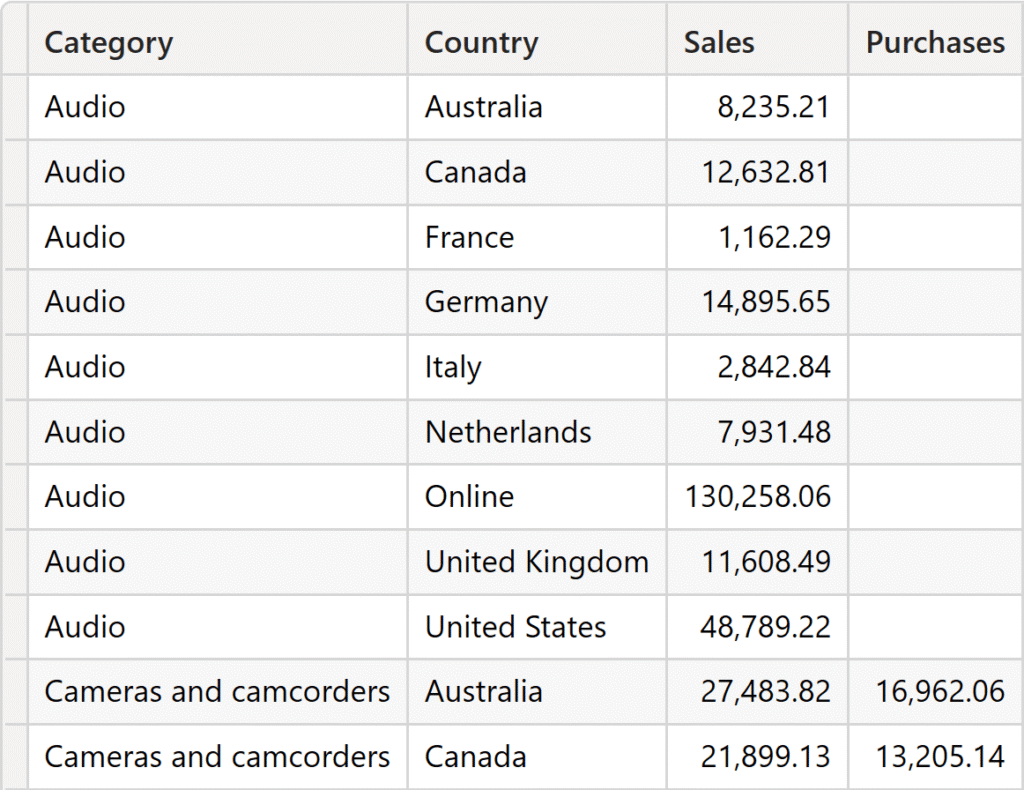
برای نشان دادن این موضوع، یک جدول Purchases به مدل اضافه شده است. جدول Purchases هیچ محصولی از دسته Audio ندارد.
فرض کنید میخواهیم مقدار Sales و Purchases را همزمان دریافت کنیم در حالی که گروهبندی بر اساس Product[Category] و Store[Country] انجام شود. این هدف را میتوان با SUMMARIZECOLUMNS به راحتی محقق کرد:
EVALUATE
SUMMARIZECOLUMNS (
Product[Category],
Store[Country],
"Sales", [Sales Amount],
"Purchases", [Purchase Amount]
)
ORDER BY
Product[Category],
Store[Country]
همانطور که مشاهده میکنید، نتیجه هیچ خریدی برای محصولات Audio ندارد، اما مقدار فروش (Sales Amount) محصولات Audio نمایش داده میشود.
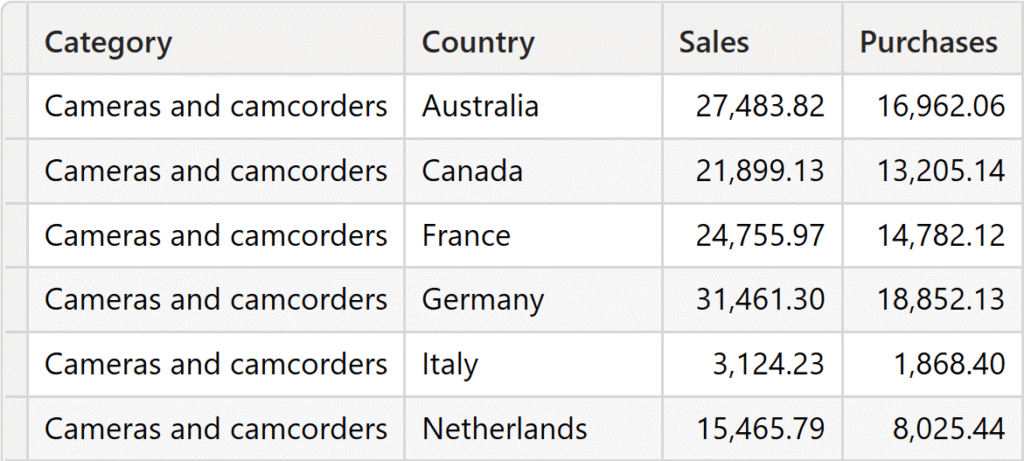
دستیابی به همان نتیجه با استفاده از SUMMARIZE بسیار دشوارتر است، زیرا SUMMARIZE نیاز دارد که جدول منبع (Source Table) مشخص شود. در این مثال، SUMMARIZE نتیجه مشابهی تولید میکرد اگر جدول Sales را به عنوان آرگومان جدول ارائه میدادیم. با این حال، اگر جدول Purchases را به عنوان آرگومان جدول انتخاب کنیم، هیچ فروش (Sales) برای محصولات Audio نمایش داده نخواهد شد.
EVALUATE
ADDCOLUMNS (
SUMMARIZE ( Purchases, Product[Category], Store[Country] ),
"Sales", [Sales Amount],
"Purchases", [Purchase Amount]
)
ORDER BY
Product[Category],
Store[Country]
نتیجه، محصولات Cameras و Camcorders را در سطرهای اول نمایش میدهد و هیچ محصولی از دسته Audio وجود ندارد.
در این مثال دمو، شروع گروهبندی از جدول Sales کافی است؛ در واقع، جدول Sales شامل تمام محصولات میباشد. با این حال، در یک سناریوی واقعی، توزیع دادهها میتواند متفاوت باشد و هیچ راهی برای تعیین نقطه شروع صحیح برای گروهبندی وجود ندارد.
بنابراین، تنها گزینه امن این است که هر دو جدول را به صورت جداگانه گروهبندی کنید، ترکیبهای گروهبندی (Group-by Tuples) را شناسایی کنید و سپس نتایج جزئی را در مرحله بعد به هم متصل کنید.
EVALUATE
VAR P =
ADDCOLUMNS (
SUMMARIZE ( Purchases, Product[Category], Store[Country] ),
"Purchases", [Purchase Amount]
)
VAR S =
ADDCOLUMNS (
SUMMARIZE ( Sales, Product[Category], Store[Country] ),
"Sales", [Sales Amount]
)
VAR Ax =
DISTINCT (
UNION (
SELECTCOLUMNS ( P, Product[Category], Store[Country] ),
SELECTCOLUMNS ( S, Product[Category], Store[Country] )
)
)
VAR Result =
NATURALLEFTOUTERJOIN ( NATURALLEFTOUTERJOIN ( Ax, S ), P )
RETURN
Result
ORDER BY
Product[Category],
Store[Country]
با اینکه این کد عمل میکند، اما بسیار پیچیدهتر از نسخه SUMMARIZECOLUMNS است. بنابراین، کندتر بوده و احتمال بروز خطا در آن بیشتر است.
یک راه حل دیگر و سادهتر، اگرچه با عملکرد ضعیفتر همراه است، استفاده از ADDCOLUMNS و انجام دستی Cross-Join ستونهای گروهبندی میباشد:
هر دو تکنیک بالا به خوبی کار میکنند، اما عملکرد باید در سناریوی خاص شما مورد ارزیابی قرار گیرد. استفاده از SUMMARIZECOLUMNS نیازمند درک عمیقتر جزئیات بیشتری است. با این حال، سمانتیک آن نسبتاً ساده است اگر تنها از قابلیتهای گروهبندی استفاده کنید و آرگومانهای فیلتر را در SUMMARIZECOLUMNS به کار نبرید.
گروهبندی و فیلترگذاری
استفاده از فیلترها در SUMMARIZECOLUMNS میتواند خطرناک باشد و توصیه میکنیم از آنها اجتناب کنید. فیلترها در SUMMARIZECOLUMNS دارای سمانتیک بسیار پیچیدهای هستند و با ستونهای گروهبندی تعامل دارند، که میتواند منجر به مشکلاتی در Coalesced Filters شود.
اگر نیاز دارید که فیلترها را در SUMMARIZECOLUMNS اعمال کنید، بهترین گزینه این است که SUMMARIZECOLUMNS را درون یک CALCULATETABLE خارجی قرار دهید:
--
-- Do NOT use this pattern, which places a filter inside SUMMARIZECOLUMNS
--
EVALUATE
SUMMARIZECOLUMNS (
Product[Brand],
Customer[Continent],
TREATAS ( { "Red", "Blue" }, Product[Color] ),
"Sales", [Sales Amount]
)
--
-- Use this pattern instead, with the filter created by CALCULATETABLE
--
EVALUATE
CALCULATETABLE (
SUMMARIZECOLUMNS (
Product[Brand],
Customer[Continent],
"Sales", [Sales Amount]
),
TREATAS ( { "Red", "Blue" }, Product[Color] )
)
استفاده از CALCULATETABLE نه تنها فیلترها را خارج از SUMMARIZECOLUMNS قرار میدهد و از تعامل بین فیلترهای داخلی SUMMARIZECOLUMNS و ستونهای گروهبندی جلوگیری میکند، بلکه Context Transition را نیز انجام میدهد و تضمین میکند که هیچ Row Context فعالی هنگام اجرای SUMMARIZECOLUMNS وجود نداشته باشد.
این روش ساده نوشتن کد DAX باعث میشود فرمول بسیار قابل فهمتر و کمخطاتر باشد.
جمعبندی
کوئریهای Power BI به تمام قابلیتهای SUMMARIZECOLUMNS نیاز دارند؛ نیاز به زیرجمعها (Subtotals)، فیلترهای NONVISUAL و تعاملات پیچیده باعث میشود Power BI از SUMMARIZECOLUMNS استفاده کند، زیرا نوشتن کوئری معادل با SUMMARIZE یا بسیار پیچیده یا حتی غیرممکن خواهد بود.
علاوه بر این، توسعهدهندگان Power BI در مایکروسافت دارای دانش بسیار عمیق درباره SUMMARIZECOLUMNS هستند؛ بنابراین بسیار محتمل است که آنها همه قابلیتها را به درستی و با درک کامل استفاده کنند. توسعهدهندگان عادی DAX احتمالاً نتایج نادرست به دست میآورند، صرفاً به این دلیل که ممکن است برخی جزئیات ظریف را فراموش کنند.
استفاده از SUMMARIZE برای محاسبه ستونهای جدید را متوقف کرده و به جای آن از ADDCOLUMNS / SUMMARIZE استفاده کنند، زیرا پیچیدگی عملیات Clustering باعث میشد SUMMARIZE برای محاسبه ستونها بسیار دشوار باشد. در اینجا، سناریو مشابه است.
SUMMARIZECOLUMNS یک تابع قدرتمند و پر از قابلیتهای متنوع است. اکثر عملیات آن به صورت خودکار انجام میشود و در بیشتر سناریوها، نتیجه مورد انتظار را تولید میکند. با این حال، زمانی که سناریو دیگر ساده نباشد، پیچیدگی رفتار آن میتواند نتایج غیرمنتظرهای تولید کند که غالباً شبیه یک باگ به نظر میرسد.
در DAX، نیازی به ایجاد کدی پیچیدهتر از حد لازم نیست. رعایت Best Practices ارائه شده در این مقاله تضمین میکند که بتوانید از SUMMARIZECOLUMNS در Measures خود استفاده کنید بدون افزایش پیچیدگی آنها و در عین حال از بهترین عملکردی که این تابع ارائه میدهد بهرهمند شوید.
اگر به حوزه های تحلیل داده , هوش تجاری (BI) و مصورسازی داده ها و ابزارهایی مانند Power BI علاقه مند هستید, با ثبت ایمیل خود به جمع مخاطبان ما بپیوندید. ما به صورت منظم , مطالب آموزشی , نکات فنی و کاربردی و منابع تخصصی را برای شما ارسال خواهیم کرد.



دیدگاهتان را بنویسید