این مقاله به بررسی نحوه تحلیل عملکرد یک معیار (Measure) در DAX میپردازد که بر پایه محاسبهی DISTINCTCOUNT ساخته شده، و چگونگی ارزیابی بهینهسازیهای ممکن را توضیح میدهد.
موتور VertiPaq توسط DAX زمانی استفاده میشود که شما مدلی را بر پایه دادههای بارگذاریشده در حافظه (in-memory) کوئری میکنید. عملکرد موتور VertiPaq در شمارش مقادیر یکتای یک ستون با استفاده از تابع DISTINCTCOUNT نیز بسیار عالی است. با این حال، شمارش مقادیر یکتا در گزارشهای پیچیده میتواند همچنان باعث بروز مشکلات عملکردی شود. دلیل اصلی این موضوع آن است که DISTINCTCOUNT یک نوع تجمیع غیرقابل جمعپذیر (non-additive) است که باید برای هر سلول در گزارش بهصورت جداگانه محاسبه شود.
درک رفتار این نوع تجمیع میتواند توضیح دهد که چرا سایر عبارات معادل، که از نظر تئوری کندتر هستند، ممکن است در برخی گزارشها عملکرد بهتری ارائه دهند.
در این مقاله نشان داده میشود که چگونه میتوان همان محاسبهی DISTINCTCOUNT را با دو روش جایگزین پیادهسازی کرد، و سپس عملکرد آنها را در گزارشهای مختلف اندازهگیری و مقایسه کرد. شما خواهید دید که اگرچه میتوان DISTINCTCOUNT را با استفاده از SUMX / DISTINCT نیز پیادهسازی کرد، اما نسخهی مستقیم DISTINCTCOUNT معمولاً عملکرد بهتری دارد – مگر در شرایطی که چگالی گزارشها بالا باشد و محاسبه فیلترهایی را اعمال کند که با سطح جزئیات گروهبندی (granularity) ویژوال تطابق نداشته باشند – همانطور که همیشه در استفاده از توابع هوش زمانی (time intelligence) اتفاق میافتد.
در برخی موارد، استفاده از SUMX / DISTINCT میتواند عملکرد بهتری ارائه دهد، اما باید مشخص شود که آیا بهینهسازی یک گزارش خاص، باعث کند شدن عملکرد بسیاری از گزارشهای دیگر خواهد شد یا نه. تنها راه برای دانستن اینکه در مدل و گزارشهای شما چه انتظاری باید داشت، اندازهگیری عملکرد با استفاده از ابزار DAX Studio است.
اندازهگیری عملکرد DISTINCTCOUNT
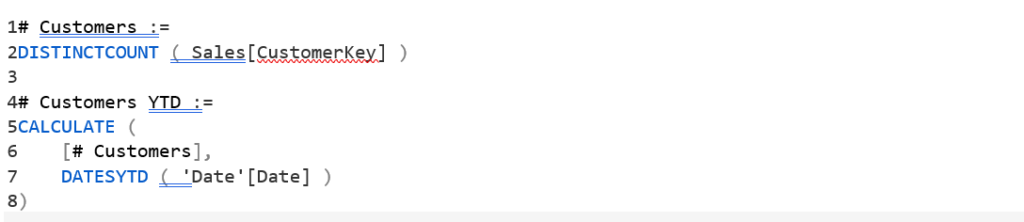
یک گزارش ساده را در نظر بگیرید که از دو معیار برای محاسبه تعداد مشتریان یکتای خریدکنندهی یک محصول استفاده میکند:
# Customers
# Customers YTD
معیار دوم (# Customers YTD) یک محاسبهی سالتابهامروز (Year-To-Date یا YTD) را روی معیار اول اعمال میکند.
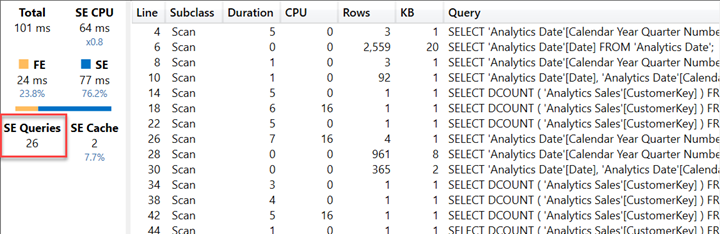
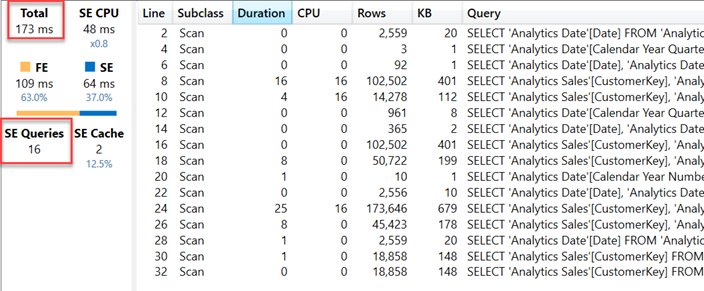
اجرای کوئری DAX که برای این ویژوالیزیشن تولید شده، نسبتاً سریع انجام میشود. با این حال، نکتهی جالب توجه، تعداد زیاد کوئریهای موتور ذخیرهسازی (Storage Engine Queries یا SE Queries) است که در طرح اجرای کوئری (Query Plan) مشاهده میشود.
این موضوع نشان میدهد که اگرچه زمان کلی اجرا ممکن است کوتاه باشد، اما پشت صحنه، موتور VertiPaq چندین بار مجبور به واکشی دادهها از حافظه شده است — که در سناریوهای پیچیدهتر یا گزارشهایی با حجم بیشتر، میتواند منجر به کاهش محسوس در عملکرد شود.
از آنجایی که محاسبهی DISTINCTCOUNTغیرقابل جمعپذیر (non-additive) است، نتیجهای که توسط موتور ذخیرهسازی (Storage Engine) تولید میشود، نمیتواند توسط موتور فرمول (Formula Engine) برای تجمیع نتایج محاسبات میانی استفاده شود.
این موضوع برای یک معیار عادی DISTINCTCOUNT مشکلی ایجاد نمیکند، چرا که برای هر سطح گرانولاریتی (سطح جزئیات) گزارش، تنها یک کوئری SE اجرا میشود.
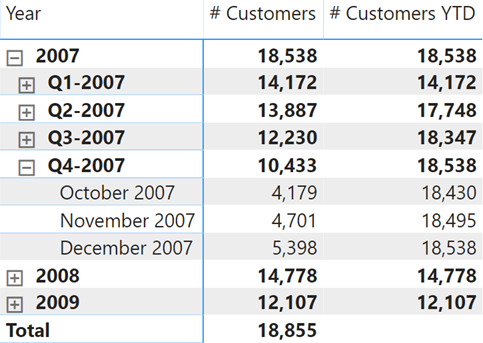
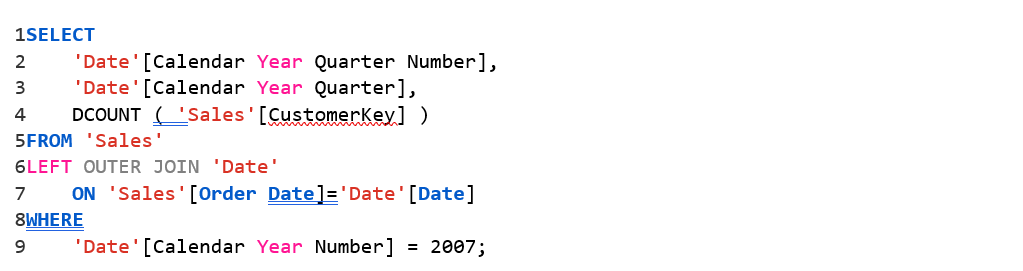
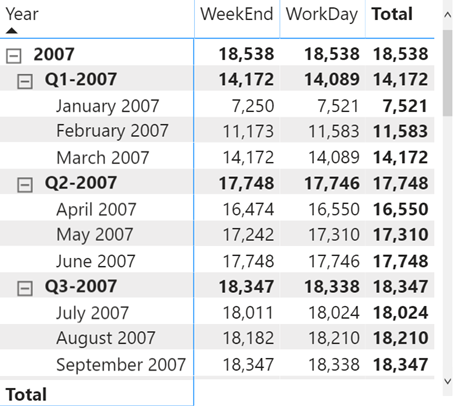
برای مثال، این همان کوئری SE است که در خط ۲۶ از اسکرینشات قبلی قابل مشاهده بود، و مربوط به محاسبهی معیار # Customers در سطح سهماهه (quarter granularity) برای سال ۲۰۰۷ است:
این کوئری SE تنها، ۴ ردیف بازمیگرداند که هر کدام مربوط به نتیجهی معیار # Customers برای یکی از فصلهای (quarters) سال ۲۰۱۷ هستند.
با این حال، ارسال یک کوئری SE تکی برای محاسبهی # Customers YTDامکانپذیر نیست، زیرا این معیار برای هر فصل، دارای یک context فیلتر متفاوت است که توسط تابع DATESYTD ایجاد میشود.
در واقع، سه فصل اول توسط کوئریهای SE موجود در خطوط ۱۴، ۱۸ و ۲۲ در اسکرینشات قبلی محاسبه شدهاند.
ساختار هر یک از این کوئریها شبیه به ساختاری است که برای محاسبهی ماه اکتبر ۲۰۰۷ استفاده شده (کد xmSQL برای خوانایی بیشتر سادهسازی شده است):
از آنجایی که هر سلول در گزارش دارای یک context فیلتر متفاوت است که از لیستی متفاوت از تاریخها تشکیل شده، امکان ساخت یک کوئری SE واحد که بهدرستی فیلترهای همپوشان (overlapping filters) موردنیاز برای اکتبر ۲۰۰۷، نوامبر ۲۰۰۷، و دسامبر ۲۰۰۷ را توصیف کند، وجود ندارد.
بهدلیل اینکه این رویکرد ممکن است پرهزینه به نظر برسد، میتوانیم گزینههای جایگزین را در نظر بگیریم.
تابع DISTINCTCOUNT در واقع چیزی نیست جز یک میانبر (syntax sugar) برای یک عبارت DAX طولانیتر که با استفاده از COUNTROWS و DISTINCT نوشته میشود:
طرح اجرای کوئری که برای مژر # Customers Basic تولید شده، با # Customers یکسان است و این دو مژر از نظر معنایی معادل یکدیگرند.
اندازهگیری عملکرد SUMX / DISTINCT
نسخهی دیگری از معیار # Customers را میتوان با جایگزین کردن COUNTROWS با SUMX ایجاد کرد، همانطور که در معیار # Customers SUMX دیده میشود:
در حالی که نتیجه مژر # Customers SUMX با نتیجه مژر # Customers یکسان است، درخواست ارسالشده به موتور DAX متفاوت است: حالا یک عبارت برای محاسبه برای هر مقدار یکتای Sales[CustomerKey] وجود دارد. اینکه این عبارت به مقدار ثابت ۱ برابر است، فقط یک حالت خاص است. حالا طرح اجرای کوئری متفاوت و پرهزینهتر است، حداقل برای گزارش قبلی.
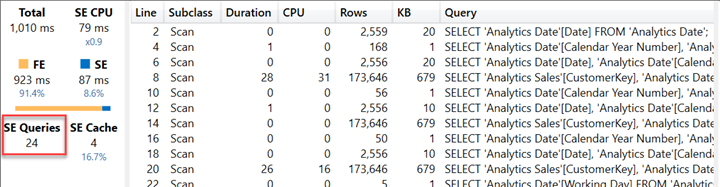
این کوئری در ۱۷۳ میلیثانیه اجرا میشود، در حالی که زمان قبلی ۱۰۱ میلیثانیه بود. تعداد کوئریهای SE کاهش یافته است، اما این تغییر تأثیر زیادی در کاهش زمان کل مصرفشده در موتور ذخیرهسازی (SE) نداشته و همچنان ۶۴ میلیثانیه است. دلیل زمان اجرای طولانیتر این است که موتور فرمول (FE) ۶۳٪ از زمان کل اجرا را مصرف میکند. کوئریهای SE در خطوط ۸، ۱۶ و ۲۴ ساختار زیر را دارند:
این کوئریهای SE یک لیست از مشتریان و تاریخها را ایجاد میکنند. موتور ذخیرهسازی دیگر دادهها را در سطح سهماهه تجمیع نمیکند، این کار اکنون بر عهده موتور فرمول است که این لیست را اسکن کرده و تعداد مقادیر یکتای روزهایی که در دوره (سال، ماه یا سهماهه) نمایش داده شده در هر سلول گزارش گنجانده شده است را میشمارد.
آیا این رویکرد همیشه کندتر است؟ بستگی دارد. اگر گزارشی داشته باشید که یک مژر را در بسیاری از سلولها نمایش میدهد و تعداد مقادیر یکتایی که باید محاسبه شوند نسبتاً کم باشد، ممکن است وضعیت متفاوت باشد. برای مثال، گزارشی را در نظر بگیرید که در آن هر سلول یک context فیلتر متفاوت دارد که با شرط گروهبندی ویژوالیزیشن تطابق ندارد. بیشتر مژرهایی که از محاسبات هوش زمانی استفاده میکنند، این شرایط را دارند. گزارش زیر از مژر # Customers YTD در یک ماتریس استفاده میکند که مقادیر را در ستونها بر اساس روز کاری گروهبندی میکند.
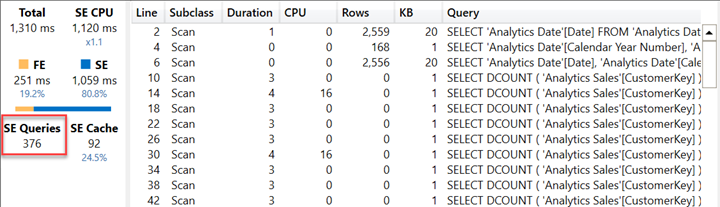
این بار نسخهای که از مژر # Customers YTD استفاده میکند، کندتر است و تعداد بسیار زیادی کوئری SE تولید میکند. هر کوئری SE به طور فردی سریع است، اما هزینه اضافی برای هر کوئری تأثیر زیادی بر نتیجه کلی دارد.
گزارش استفادهکننده از # Customers YTD۳۰٪ کندتر از همان گزارش است که از # Customers SUMX YTD استفاده میکند، اما نکته جالب این است که دلایل این موضوع را بررسی کنیم. توجه کنید به تعداد کمتر کوئریهای SE که اکنون اجرا میشوند.
معمولاً ما یک طرح اجرای کوئری را ترجیح میدهیم که زمان بیشتری را در موتور ذخیرهسازی (SE) صرف کند تا در موتور فرمول (FE). این به این دلیل است که کوئریهای SE میتوانند کش شوند، در حالی که آنچه که توسط موتور فرمول اجرا میشود باید در هر بار اجرا محاسبه شود. با این حال، زمانی که تعداد کوئریهای SE تولید شده توسط یک کوئری DAX از حد مجاز کوئریهای SE که در کش نگهداری میشوند (در حال حاضر ۲۵۶) فراتر رود، دیگر هیچ سودی از کش VertiPaq نخواهید برد.
ما به عمد گزارشهایی را انتخاب کردیم که تفاوت بین این پیادهسازیها کم بود، زیرا میخواستیم روی رفتار زیرین تمرکز کنیم. ممکن است گزارشهایی وجود داشته باشند که مژر # Customer SUMX از مژر کلاسیک # Customer مبتنی بر DISTINCTCOUNT بسیار سریعتر باشد، اما معمولاً عکس این موضوع صحیح است.
اینها عناصر مهمی هستند که هنگام مقایسه DISTINCTCOUNT با راهحل مبتنی بر SUMX / DISTINCT باید در نظر گرفته شوند:
DISTINCTCOUNT بیشتر به SE تکیه دارد.
محاسبه نتیجه برای یک سلول خاص معمولاً با استفاده از DISTINCTCOUNT سریعتر است.
یک مژر با فیلترهایی که برای هر سلول متفاوت است، بدون توجه به شرایط گروهبندی، ممکن است نیاز به کوئریهای SE اضافی داشته باشد.
تعداد کمی از کوئریهای SE ممکن است بین محاسبات در کش باقی بمانند.
پیچیدگی گزارش و تعداد سلولهای نمایش داده شده با محاسبه DISTINCTCOUNT ممکن است تعداد کوئریهای SE را افزایش دهد.
SUMX / DISTINCT دادهها را برای انجام محاسبه در FE به صورت فیزیکی ایجاد میکند.
نیاز به تعداد کمتری کوئری SE است.
ایجاد دادهها ممکن است زیاد باشد و در زمان کوئری به حافظه بیشتری نسبت به DISTINCTCOUNT نیاز داشته باشد.
اندازه ایجاد دادهها به کاردینالیته گزارش و حداکثر تعداد مقادیر یکتای که ممکن است بر اساس فیلترهای موجود در گزارش محاسبه شوند، بستگی دارد.
میتوانید ببینید که همان مدل میتواند نتایج مختلفی در گزارشهای مختلف تولید کند. شما باید به دقت عوارض جانبی پیادهسازیهای مختلف DISTINCTCOUNT را در نظر بگیرید تا از بروز عوارض جانبی ناخواسته در گزارشهای دیگر جلوگیری کنید. به عنوان مثال، نباید از SUMX / DISTINCT در DirectQuery استفاده کنید، زیرا معمولاً هزینه بیشتری نسبت به DISTINCTCOUNT بومی که در منبع داده اجرا میشود، دارد. تجزیه و تحلیل طرحهای کوئری با استفاده از DAX Studio میتواند به پیشبینی رفتارهای آینده همان مژر در گزارشهای مختلف کمک کند.







دیدگاهتان را بنویسید