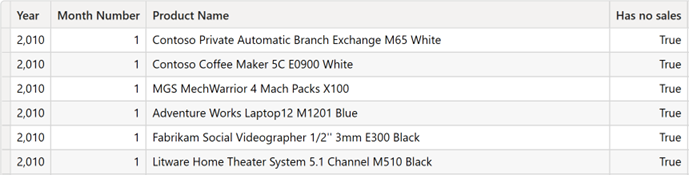
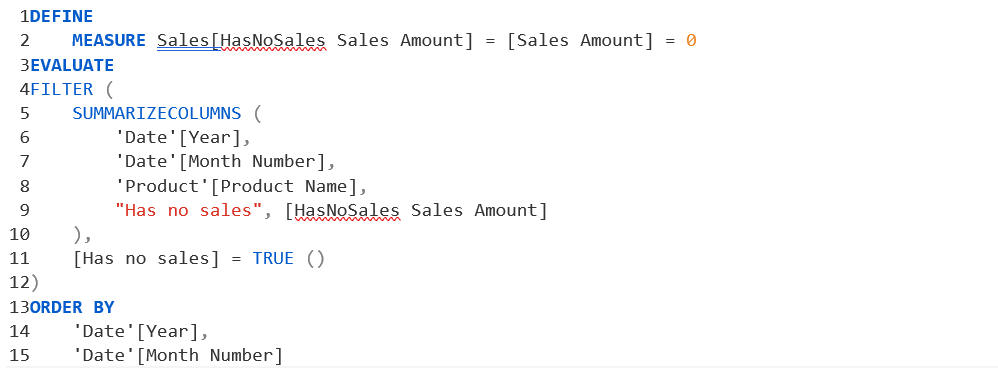
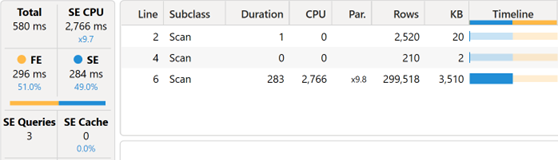
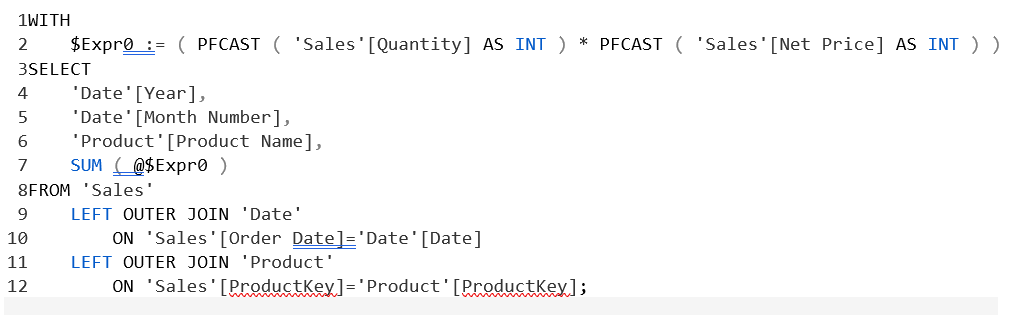
پیدا کردن محصولاتی که فروش نداشتهاند با استفاده از DAX










مطالب آموزشی




دیدگاهتان را بنویسید