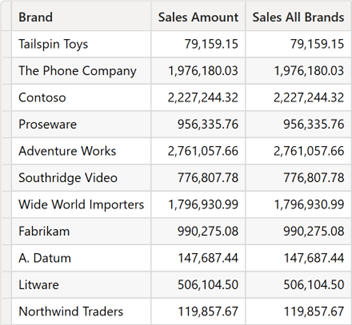
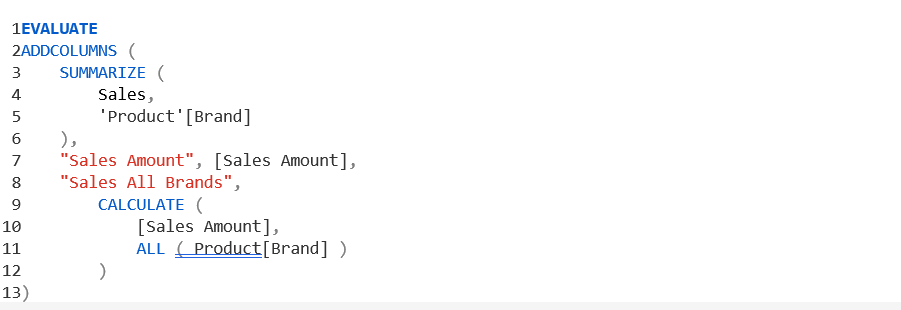
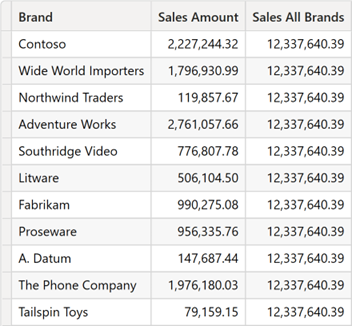
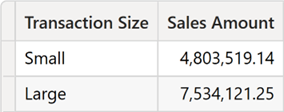
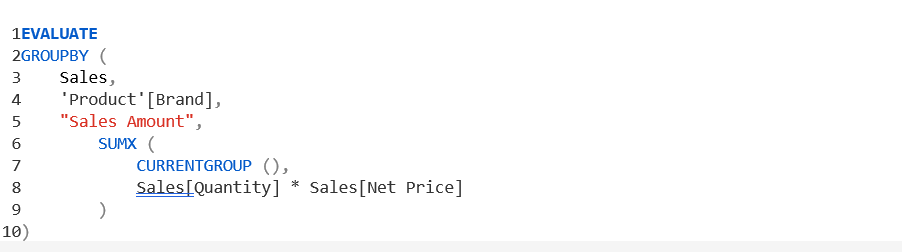
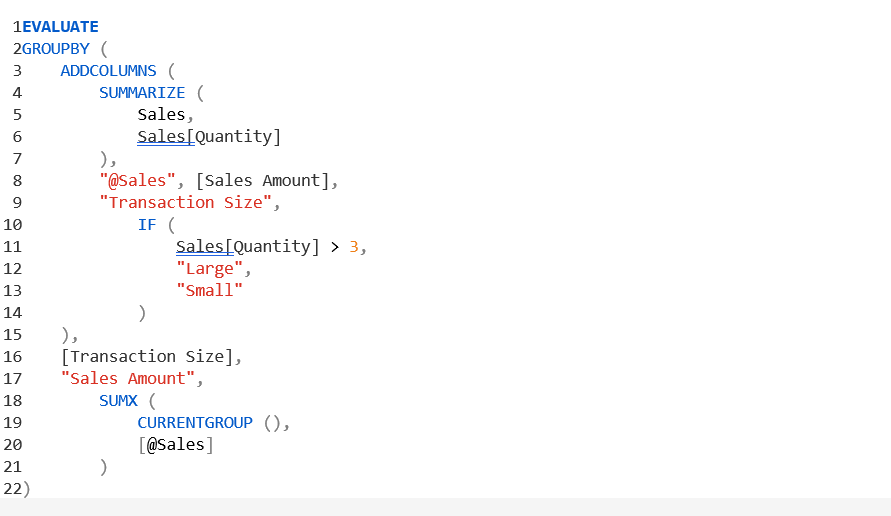
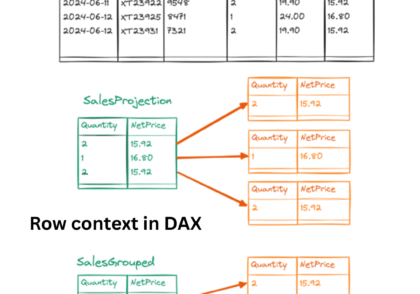
تفاوت بین GROUPBY و SUMMARIZE














مطالب آموزشی



دیدگاهتان را بنویسید