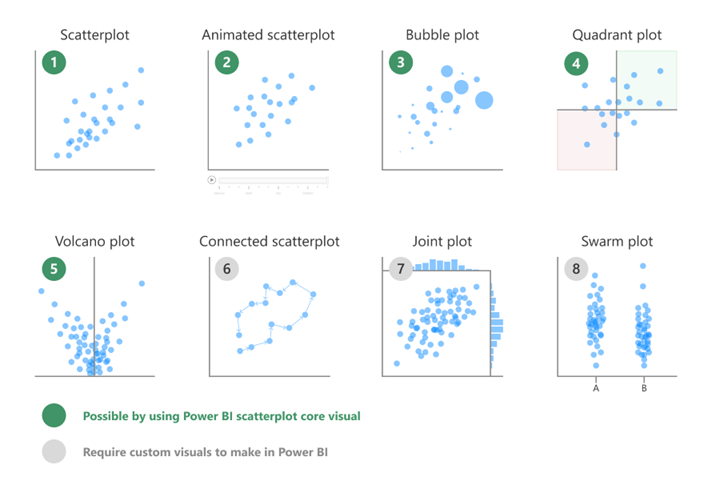
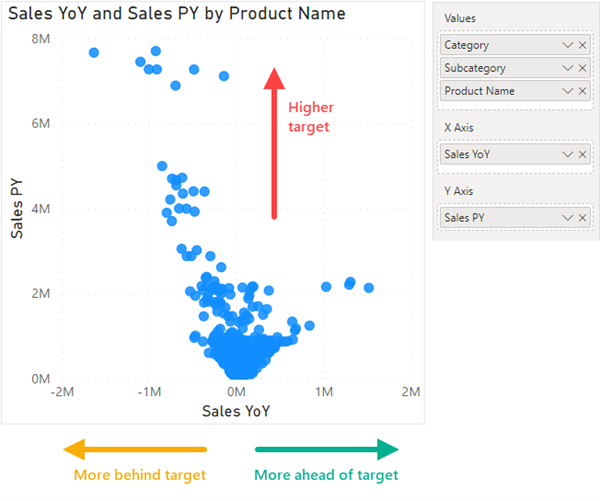
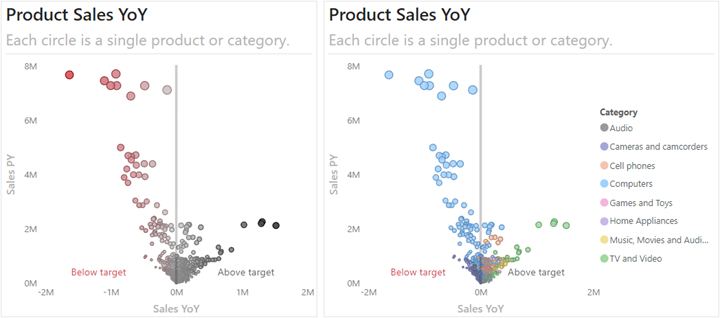
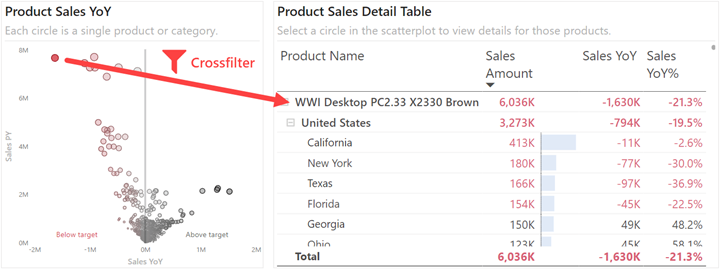
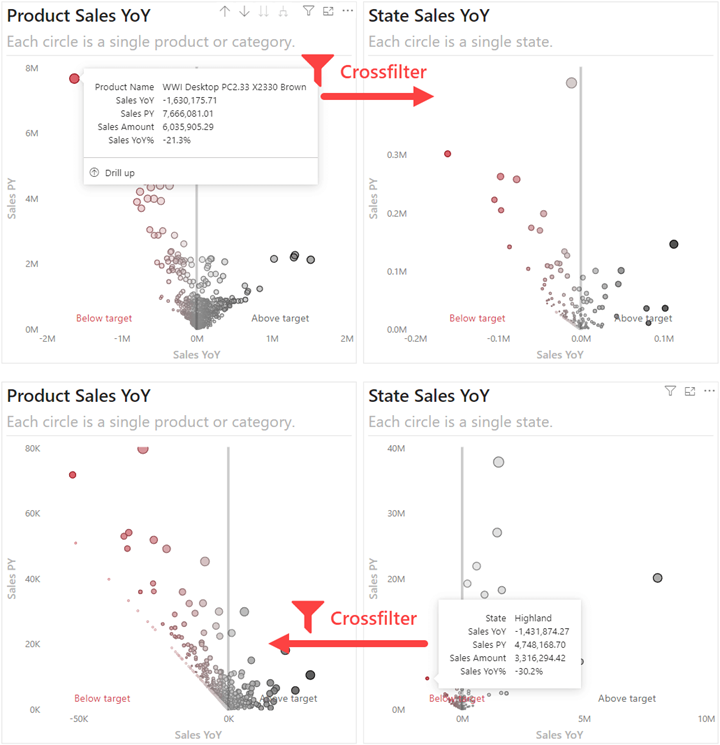
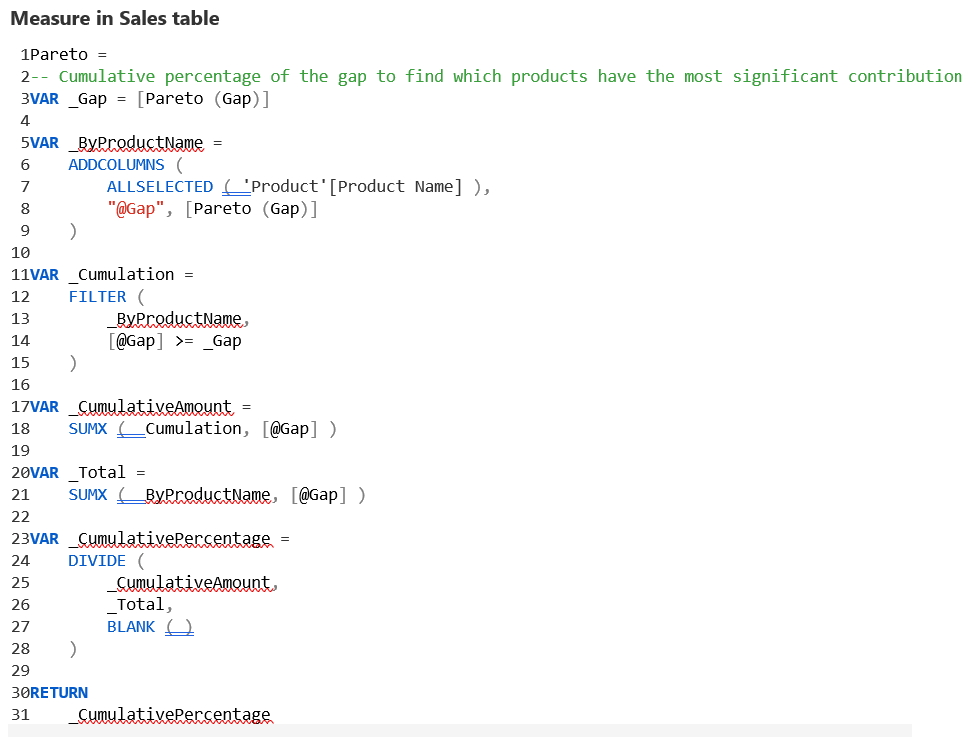
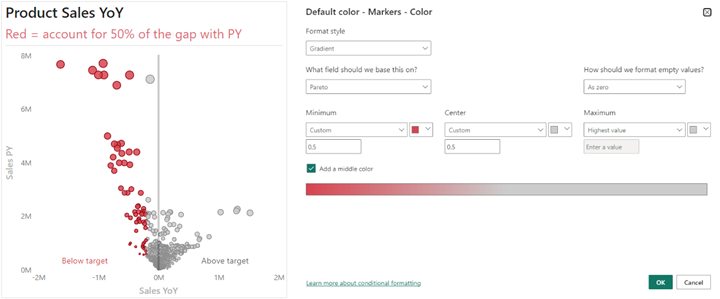
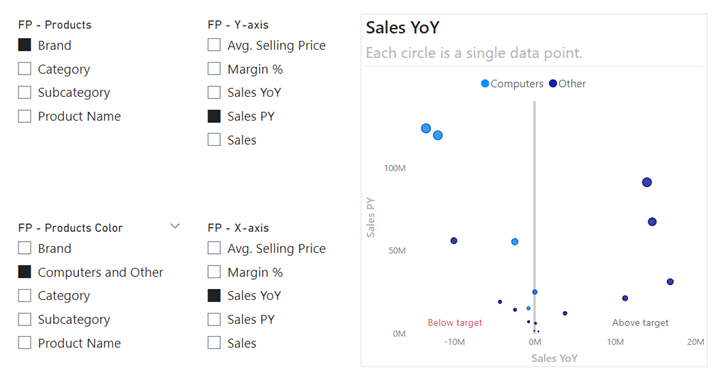
استفاده از نمودارهای پراکندگی(Scatterplot) برای یافتن جزئیات در گزارشها

مطالب آموزشی



دیدگاهتان را بنویسید